1.基本功能
1.1 创建工作流
菜单栏中点击 工作流 菜单,在工作流页面中点击 创建工作流 菜单。
在 创建工作流 弹窗中,填写工作流的 名称 和 描述,完成填写后点击 保存 按钮,完成工作流的创建。
刚创建的工作流处于 停用 状态,停用状态的工作流无法在智能体高级设置中选择。
1.2 复制工作流
作用:
- 通过复制已验证的有效工作流,可避免重复设计流程,尤其在多团队、多分支机构或跨地域协作中,能迅速统一操作标准。
- 复制工作流能强制执行统一流程,减少人为操作差异,确保业务结果的一致性。
- 复制工作流后,可对比原始版本与优化版本的执行效果,为迭代提供数据支持。
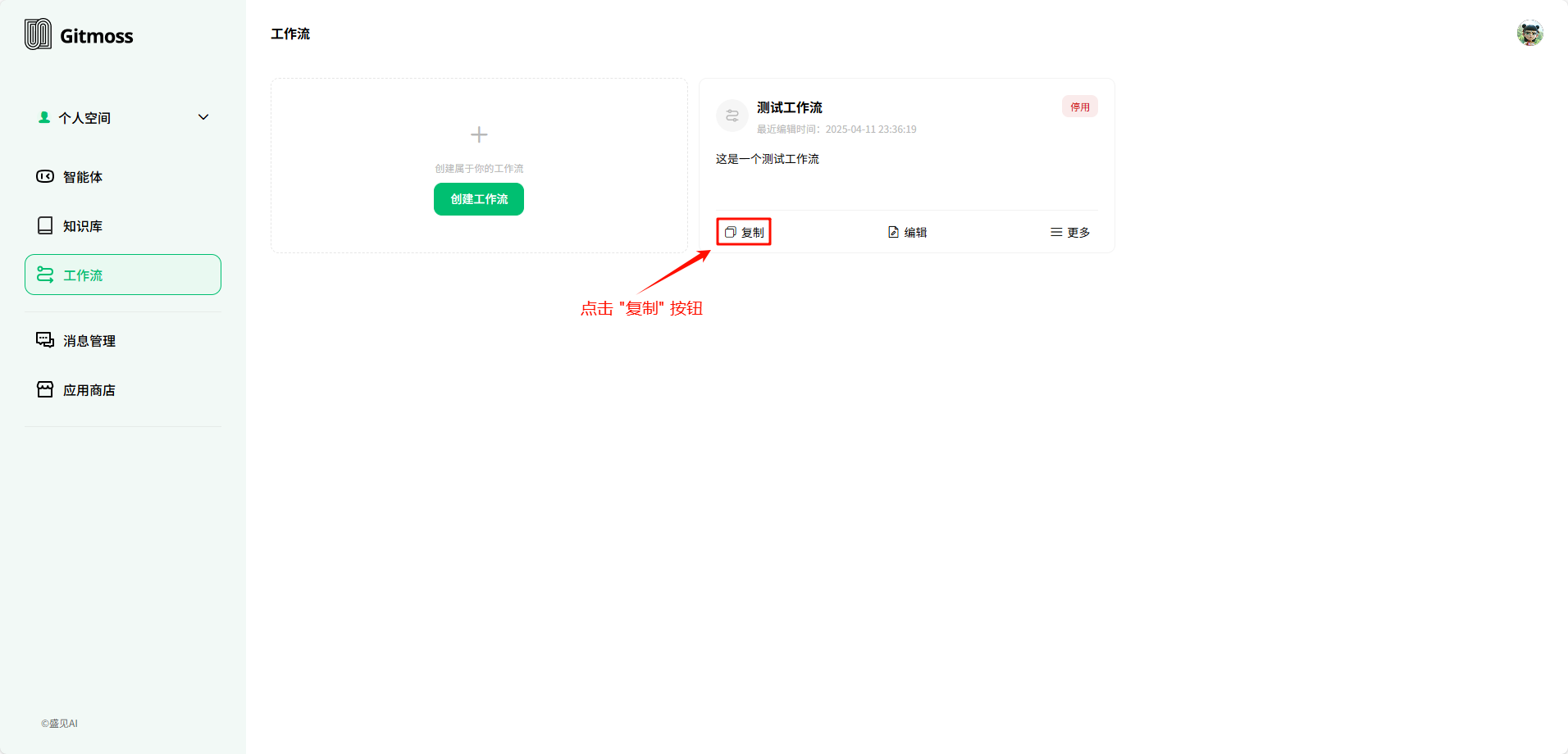
选择需要复制的工作流卡片,点击 复制 按钮。
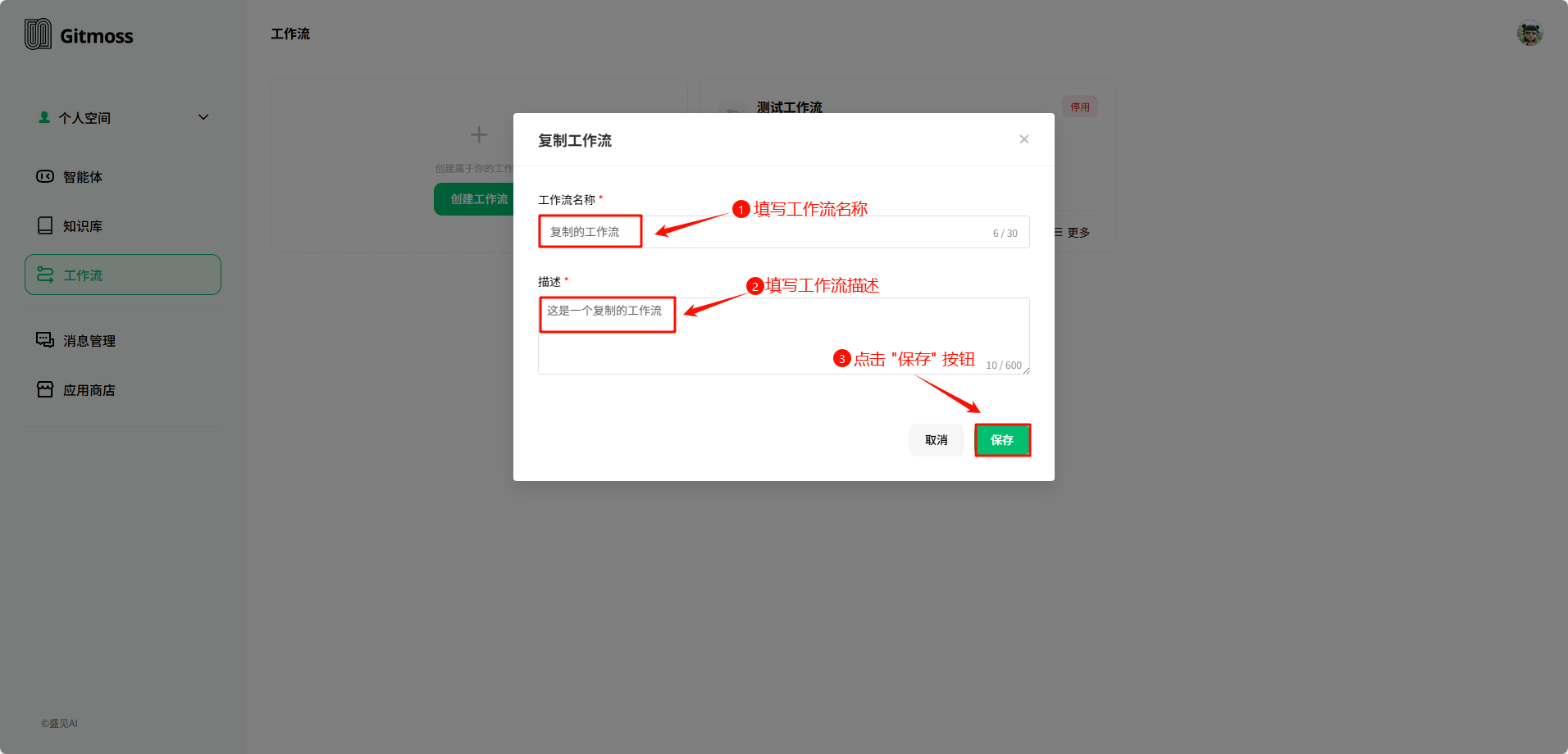
在 复制工作流 弹窗中,填写 工作流名称 和 工作流描述,填写完成后点击 保存 按钮完成工作流的复制。
1.2 启用、停用
停用 状态的工作流,点击 启用 按钮,启用工作流。
启用 状态的工作流,点击 停用 按钮,停用工作流。
1.3 删除
点击 删除 按钮,删除工作流,删除后无法恢复,请谨慎删除。
1.4 工具栏
拖拽画布
点击后,鼠标会变为 手 的样式,可以用来拖拽 画布 和 组件。

选中
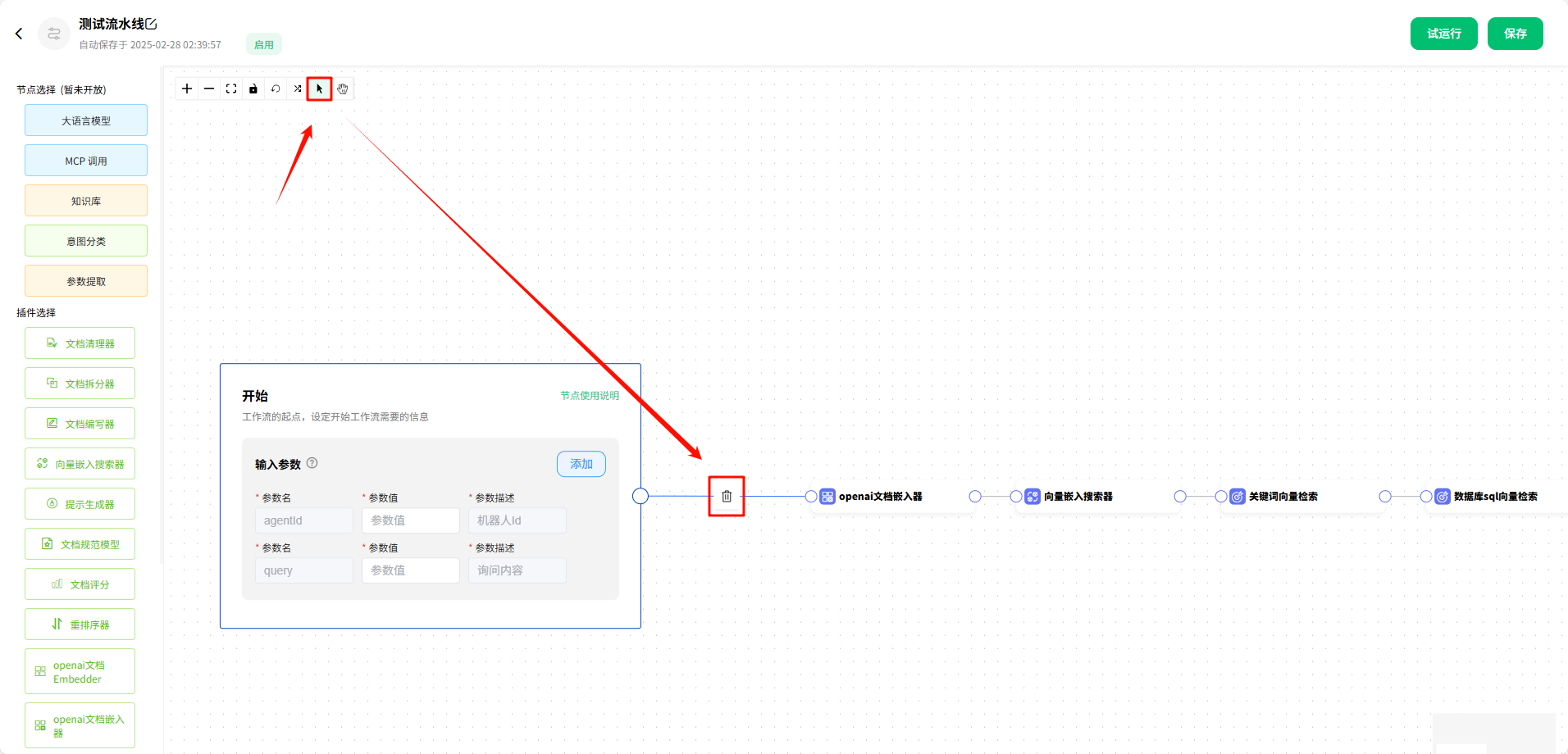
点击后,鼠标会变为 指针 的样式,可以用来选中 组件 和 连接线,从而对 组件 和 连接线 进行删除等操作。
自动化布局
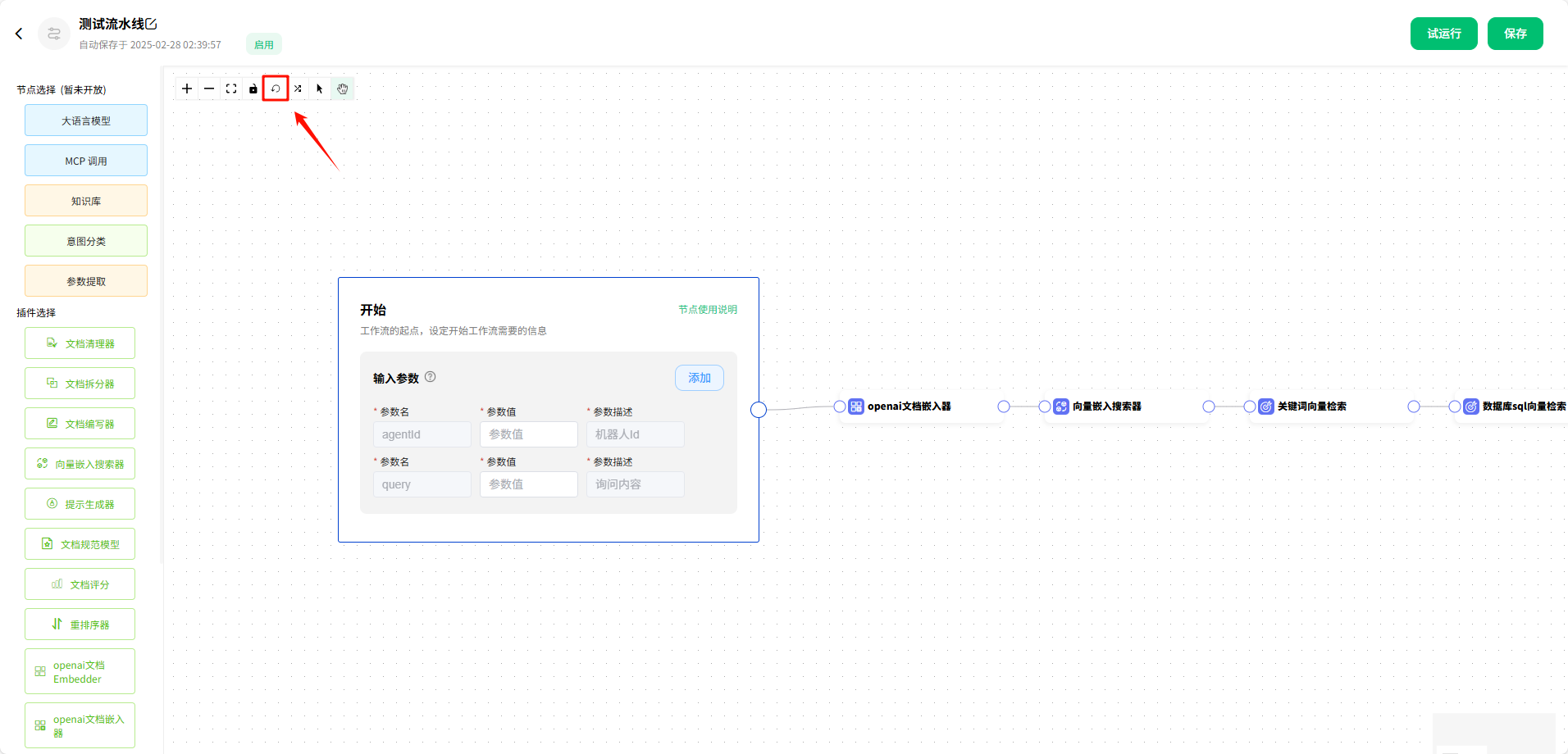
点击后,工作流会自动调整布局。

重置布局
点击后,工作流会重置布局为最开始的布局。
锁定画布
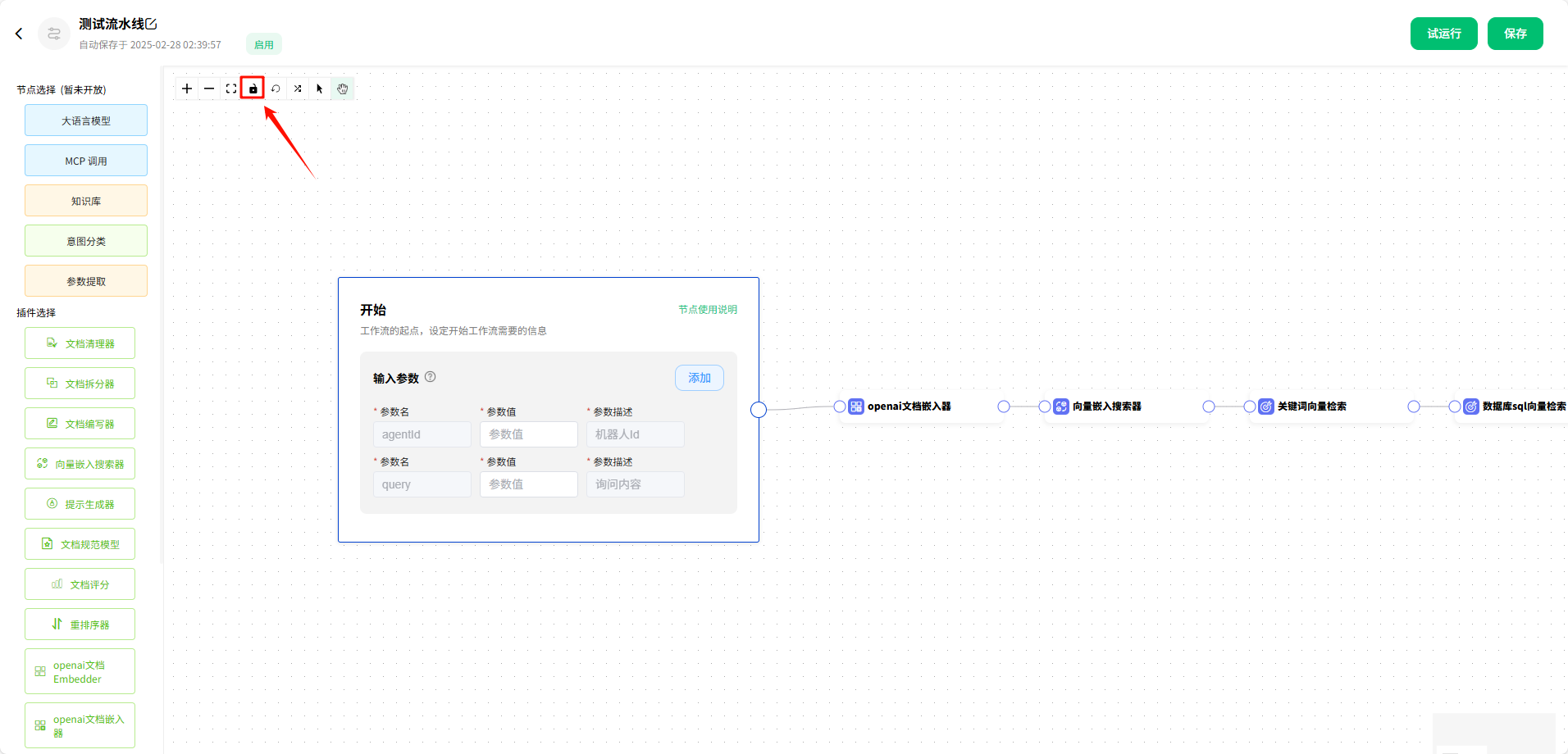
点击后,画布处于锁定状态,不可操作组件。
自适应工作流的大小
点击后,画布会自适应大小。
缩小画布
点击后,画布会缩小。
放大画布
点击后,画布会放大。
2.节点使用说明
当前可使用的节点:大语言模型、MCP 调用,其他节点仍在开发中。
2.1 大语言模型
借助 开始 节点辅助讲解 大语言模型 节点。
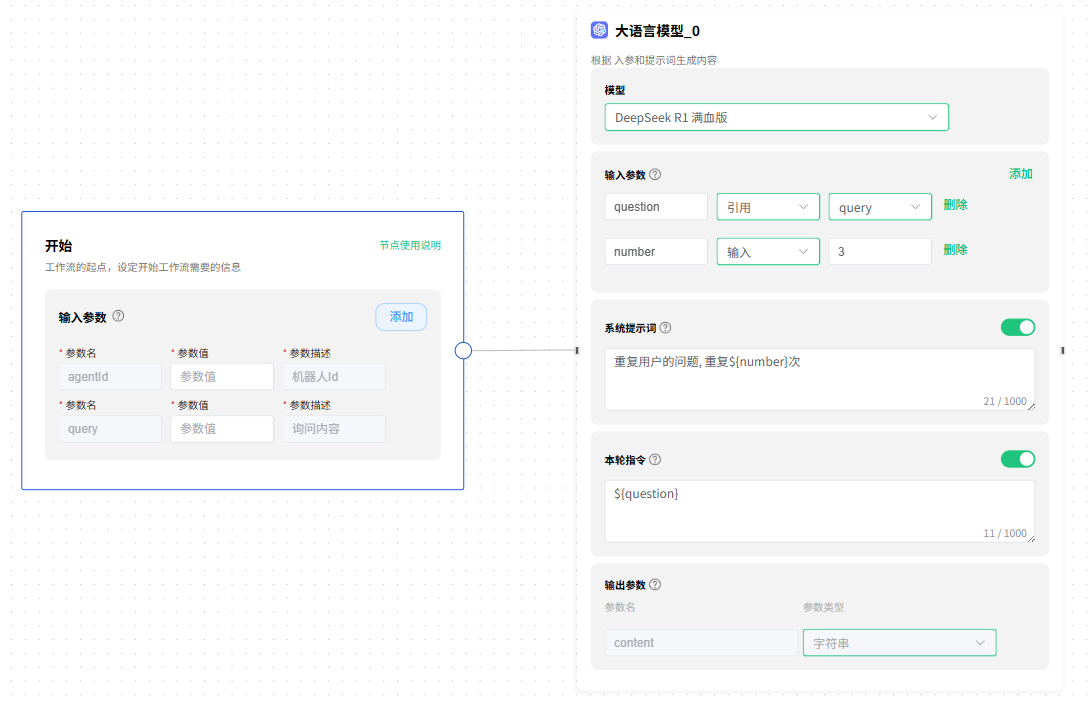
模型
用户可以点击下拉框,根据需求选择 模型。
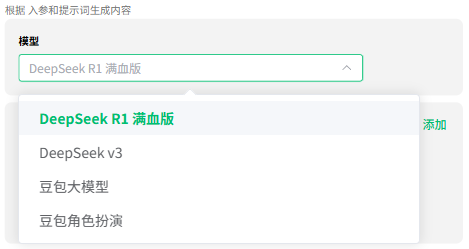
输入参数
输入参数分为两种类型:引用类型 和 输入类型。
- 引用类型:引用其他节点的参数,如图所示,我们引用了
开始节点中的query参数,并给他重命名为question,当然也可以继续沿用之前的名称。 - 输入类型:手动输入
参数名称和参数值,如图所示,我们定义可一个参数number,值为3。
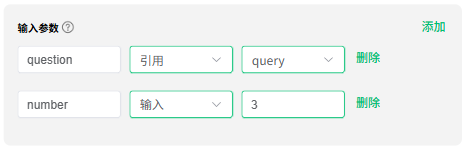
系统提示词
用来定义模型的角色,也就是我们系统大语言模型所扮演的角色,它的能力,以及你希望它在跟你对话或者帮助你生成内容时的一些规则。
例如:
# 以一个历史学家的角色来开启对话
"你是一个著名的历史学家,你精通中国上下五千年的历史,并且擅长用小学生听得懂的语言讲解历史,幽默风趣又不失端庄稳重。"
本次案例中,给模型定义的角色是 复读机,重复用户的问题,重复 ${number} 次,这里的 ${number} 使用的上面定义的参数。
"你是一个复读机,重复用户的问题,重复${number}次" 等同于 "你是一个复读机,重复用户的问题,重复3次"。
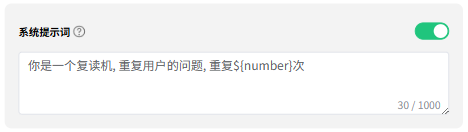
本轮指令
指的是具体你要模型帮你做的事情,例如写一篇作文等等。
本次案例中使用的是 ${question} 参数,${question} 参数引用的是 开始 节点中 query 的值,query 是用户输入的内容,也就是将用户输入的问题发给大模型。
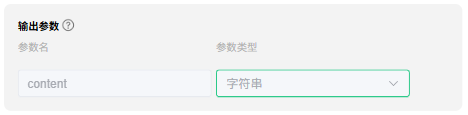
输出参数
模型的回复会给到参数 content,当你需要进行其他复杂操作时,可以引用参数 content,对 content 参数的值做进一步处理。
2.2 MCP 调用
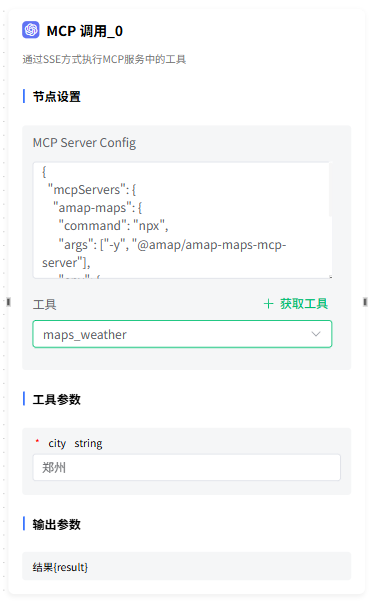
节点设置
MCP 支持的格式:Stdio、SSE。
以高德地图为例:
# stdio 的格式
{
"mcpServers": {
"amap-maps": {
"command": "npx",
"args": ["-y", "@amap/amap-maps-mcp-server"],
"env": {
"AMAP_MAPS_API_KEY": "您在高德官网上申请的key"
}
}
}
}
# sse 的格式
{
"mcpServers": {
"amap-amap-sse": {
"url": "https://mcp.amap.com/sse?key=您在高德官网上申请的key"
}
}
}
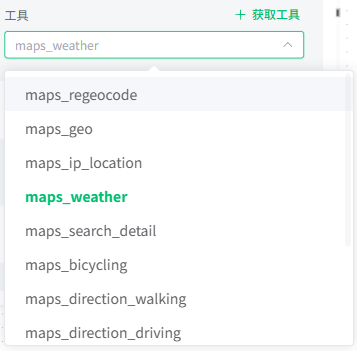
工具
填写 MCP 配置 后,点击 获取工具 按钮,可以获取配置的 MCP 的工具列表,在下拉框中选择需要使用的工具。
工具参数
调用该工具时传入的参数示例。

输出参数
调用工具后得到的结果。

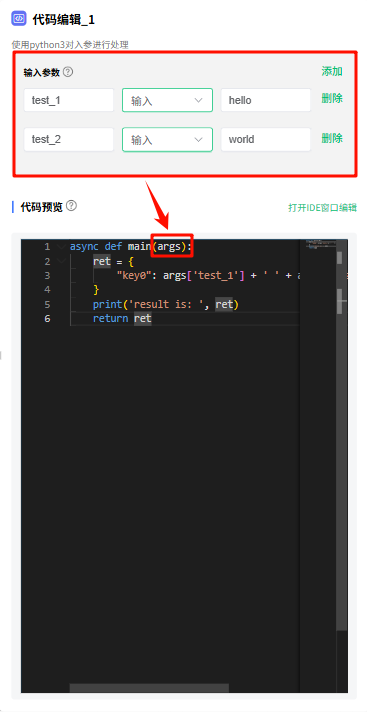
2.3 代码编辑
输入参数
输入参数可以被代码预览中的 args 引用。
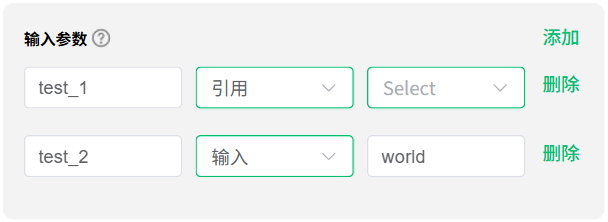
输入参数支持 输入 和 引用 两种方式:
- 输入:可自由输入参数
- 引用:引用其他节点或插件的参数
代码预览
支持使用 Python 编写一个函数,引用输入变量进行处理,然后返回输出参数。
不支持写多个函数,函数的输出类型必须是对象。
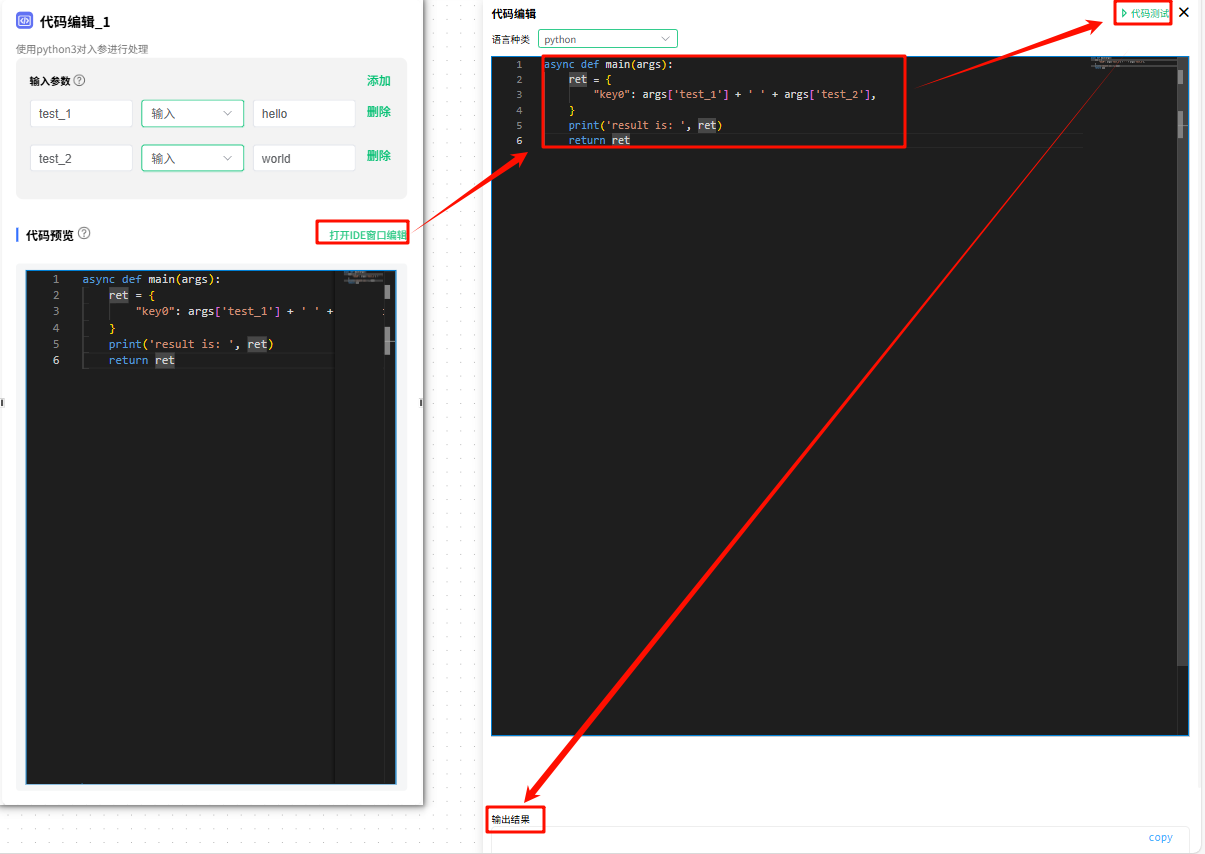
点击 打开IDE窗口编辑 按钮,会在右侧出现一个 代码编辑 窗口,输出需要执行的代码,点击 代码测试 按钮,进行代码调试,代码调试的结果会在下方显示。

3.插件使用说明
3.1 文档清理器
文档清理器 用于提高文本文档的可读性和处理效率。它系统性地删除用户上传文档中的额外 空格、空行、指定的子字符串、通过 正则表达式 匹配的内容、以及常见的 页面页眉 和 页脚 等无关信息。通过这些清理操作,文档清理器 能够显著提升文档的质量,使其更加简洁和结构化。

3.2 文档拆分器
文档拆分器 能够智能识别用户上传文档的内容,并根据内容特点灵活选用按 章节、语义单元 或 句子 等方式进行拆分,将大型文档合理切分成多个较小的块或段落。这种细粒度的分割方式有助于模型更精准、高效地理解和处理信息,提升后续任务(如信息检索、问答系统、文本摘要等)的效果。

3.3 文档编写器
文档编写器 负责将处理后的文档写入文档存储库,以便在后续步骤中能够高效地检索和使用这些文档。

3.4 向量嵌入搜索器
向量嵌入搜索器 是一个用于执行向量嵌入搜索的组件,通过将文本数据转换为向量表示,并存储在支持向量相似度查询的数据库中,向量嵌入搜索器 能够实现快速且准确的语义搜索。

3.3 提示生成器
提示生成器 是一个用于动态生成提示(Prompt)的组件,它的主要作用是根据输入数据、上下文信息和任务需求,灵活地构建适合大语言模型(LLM)或其他下游任务的提示文本。这种动态生成提示的能力可以显著提升系统的灵活性和适应性,特别是在复杂或多样化的应用场景中。

3.4 文档规范模型
文档规范模型 能够对检索到的各类文档进行统一的规范化和格式化处理,确保所有文档符合预定义的标准格式。这包括但不限于去除冗余信息、标准化文本结构、统一编码格式等操作。通过这种标准化处理,文档规范模型 为后续的处理流程(如信息抽取、语义搜索、相似度匹配等)提供了高质量且一致的数据支持,从而提升整个系统的准确性和效率。

3.5 文档评分
根据用户提出的问题,系统会从用户的文档集合中提取多个与问题高度匹配的段落,并通过 文档评分器 对这些段落进行量化评估。每个段落将基于其与问题的相关性、内容的质量以及其他预定义的标准获得一个具体的得分。匹配度越高的段落得分越高,反之则得分越低。这种评分机制不仅帮助系统精准地筛选出最相关的段落,还确保了最终呈现给用户的答案具有最高的质量和相关性。

3.6 重排序器
当用户提出一个问题时,系统会从大量可能相关的文档或答案中初步筛选出一批结果。然而,这些结果中可能夹杂着一些不完全相关或者质量较低的内容。这时, 重排序器 就像一位“质检员”,对这些初步筛选出的结果进行二次评估和排序。它通过分析每个结果与问题的相关性、内容的质量等因素,将真正有用的信息排到前面,确保最终呈现给用户的答案更加精准和相关。

3.7 openai 文档 Embedder
利用 OpenAI 提供的先进嵌入模型,将用户上传的文本数据转换为高维向量表示。这些嵌入向量能够精确捕捉文本的语义信息,使得系统能够在大规模文档集合中进行高效的语义搜索和相似性比较。通过这种方法,可以提升信息检索的准确性。

3.8 openai 文档嵌入器
利用 OpenAI 提供的强大嵌入模型,将用户的查询转化为高维向量表示。这种转换不仅捕捉了查询的语义信息,还使得能够在预先构建的向量数据库中高效地匹配相似的文本内容。通过这种方法,系统能够实现精准的语义搜索,提升信息检索的准确性和用户体验。

3.9 自定义全文本
使用 自定义全文本 插件后,系统将不再对查询到的答案进行评分或排序操作,而是直接将所有匹配到的答案完整地传递给下游模型以获取最终回复。这种处理方式跳过了传统的评分和排序步骤,确保了答案的完整性与多样性,同时也为模型提供了更丰富的上下文信息,从而有助于生成更加全面和精准的响应。

3.10 知识图谱检索
知识图谱检索 插件适用于依赖知识图谱知识库的场景,专门用于从结构化或半结构化的知识图谱中查找与用户问题相匹配的信息。它通过解析用户的查询,并将其映射到知识图谱中的实体和关系,从而精准定位相关联的知识节点,提取出能够回答问题的具体文本内容或数据片段。

3.11 上下文记忆
上下文记忆 插件提供了强大的上下文记忆功能,使模型能够在对话过程中保持对之前交互内容的记忆和理解,而不仅仅局限于当前的单词或句子。这种能力使得模型能够更好地处理连续对话,维持对话的一致性和连贯性,并根据之前的对话历史提供更加个性化和相关的回复。

3.12 关键词向量检索
关键词向量检索 是指从用户提出的问题中提取出关键术语或短语,用于从数据库中并将这些关键词转换为向量表示,然后基于这些关键词向量在数据库中进行匹配和检索,以找到与用户问题最相关的数据。

3.13 数据库 sql 向量检索
在使用数据分析知识库时,数据库 sql 向量检索 插件会根据用户提出的问题,结合知识库中存储的文档和信息,智能生成与问题相关的 SQL 查询语句。随后,系统会执行该 SQL 语句,从数据库中提取所需的数据,并将结果以清晰、直观的方式返回给用户。

3.14 合并检索
当系统同时使用了多种知识库(如 普通文档知识库、结构化的 知识图谱知识库、以及用于 数据分析的数据库 等)时,会分别从这些知识库中检索与用户问题相关的数据。随后,系统会对来自不同知识库的检索结果进行整合和统一处理,确保信息的连贯性和一致性,并将合并后的数据传递给下游模型,从而生成全面且精准的回复。

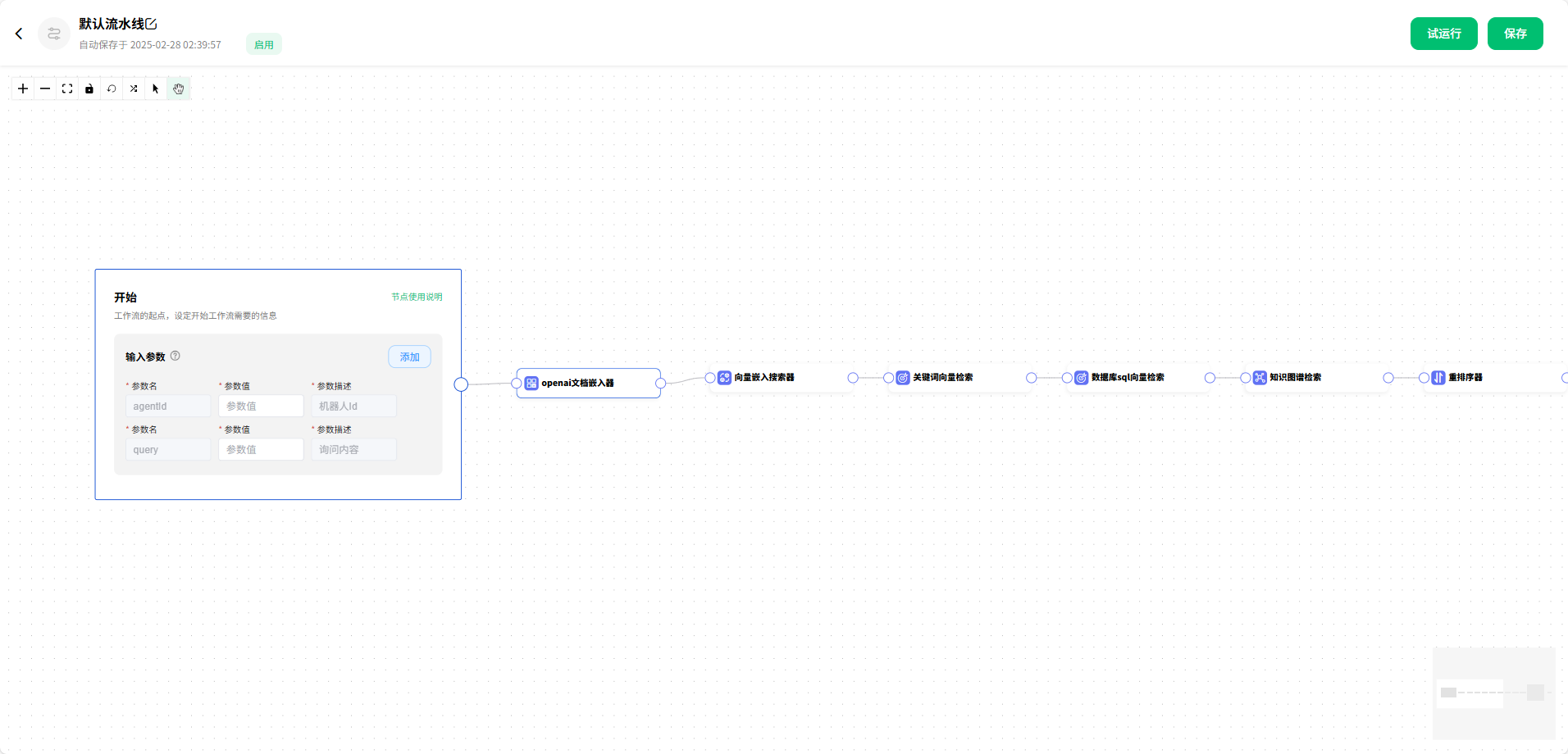
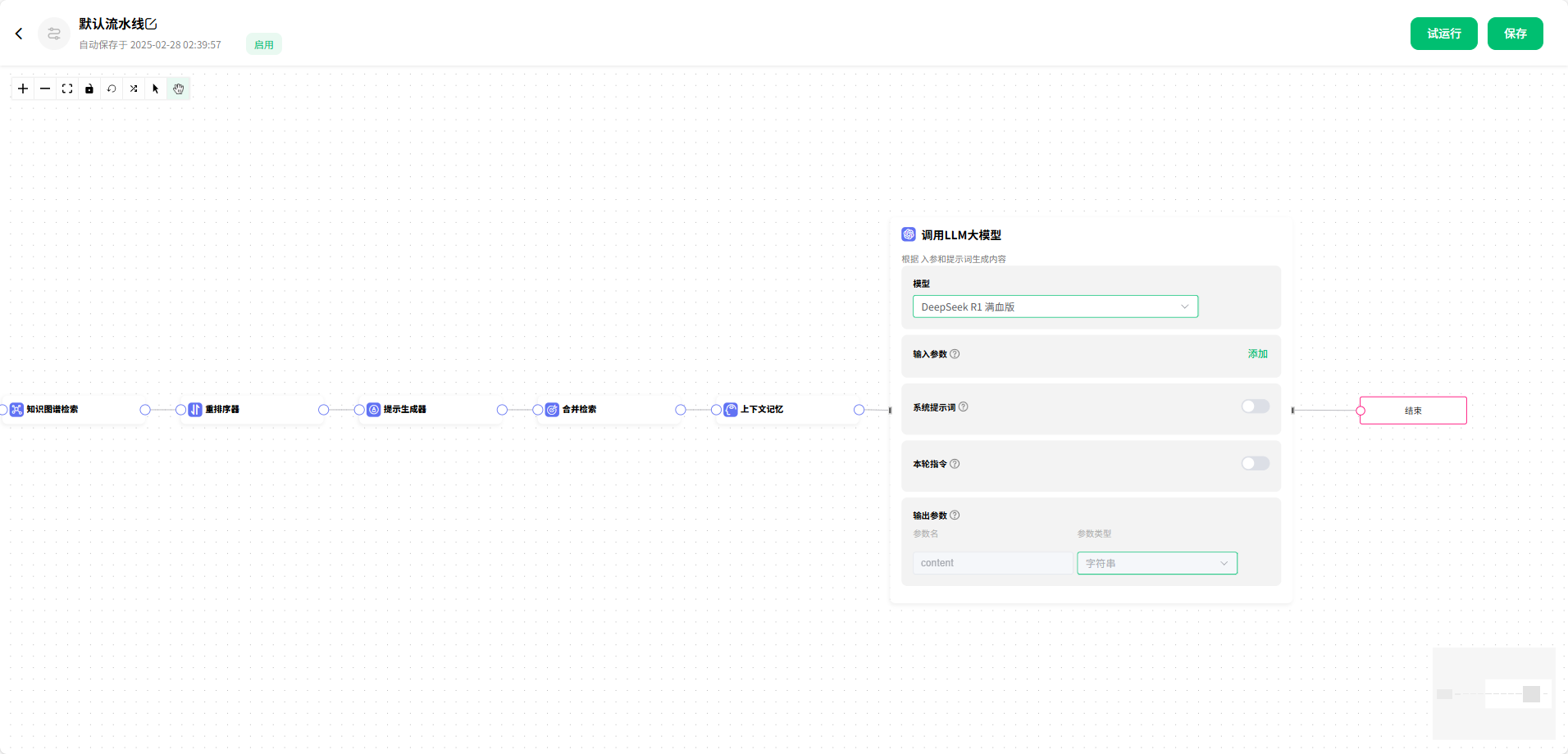
4.默认流水线
下面为 默认流水线 的工作流,作为参考,可以按照自己的需求进行修改,制作出符合自己需求的工作流。
流程:开始节点 → openai文档嵌入器 → 向量嵌入搜索器 → 关键词向量检索 → 数据库sql向量检索 → 知识图谱检索 → 重排序器 → 提示生成器 → 合并检索 → 上下文记忆 → 调用LLM大模型 → 结束节点